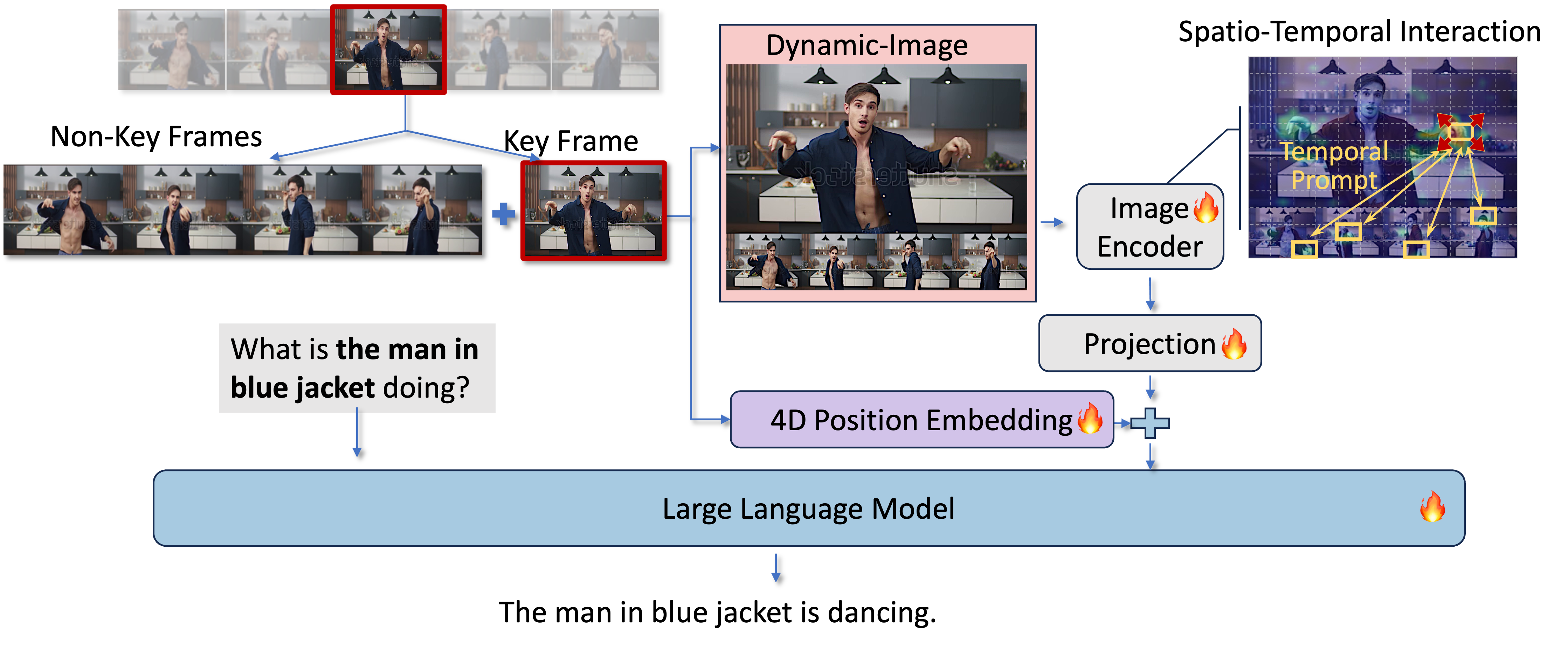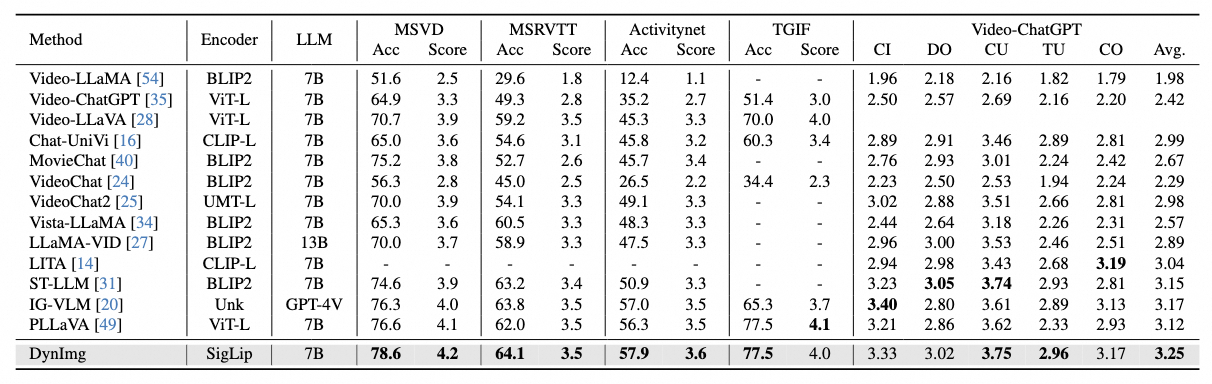
Structure Comparison between the previous methods for video understanding and DynImg. Previous models use processed visual features for subsequent spatial and temporal merging modules, either in parallel (a) or in sequence (b). However, in rapidly moving scenarios like the example on the right, where the little girl quickly turns back and moves in the last frame, these models fail to capture the crucial details of her motion. Factors such as motion blur lead to these important temporal details being overlooked during the visual feature extraction process, resulting in these areas not receiving the necessary attention. Spatio-temporal interaction based on such inaccurate features or tokens is ineffective. In contrast, our proposed DynImg (c) advances the spatio-temporal interaction process via temporal prompts. This enables the model to focus on those rapidly moving regions that are difficult to capture during the feature extraction phase.